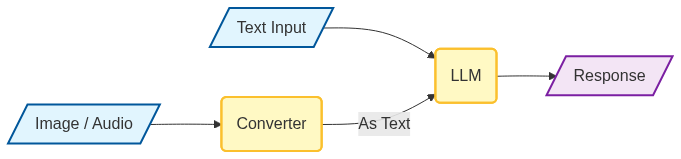
By multimodal, I mean that instead of just text being sent to the LLM, you could also provide it video, audio or an image.
The LLM itself typically still accepts text as its primary input. The process that makes multimodal integration possible happens outside the LLM. It involves separate models or processes that are specialized in interpreting the non-text data, like images or audio. These models extract relevant information from the non-text data and then convert it into a text-based representation. This text representation is then fed into the LLM, allowing it to understand and respond to the combined multimodal input.
I’ve seen certain LLMs generate files, images, and charts. How does it do that?
I personally have asked the LLM to generate zip files containing code and folder structures. I’ve asked it to generate Excel files. I’ve asked the LLM to generate plots and it has been able to do all that! These examples had me scratching my head because I thought an LLM only generates text.
How is it possible that it’s generating all these other artifacts?
When you see it producing diagrams or images, it’s often because the LLM is generating the code or instructions to create those visuals. This code is then interpreted or processed by separate software components that can render the diagrams or images.
